I'm a huge fan of using the type system to make my life easier when coding. You might have already seen an allusion to this in a past post of mine on how I used the type system to make my side project more secure by default. This post goes into another place where, in addition to the type system, I used derive macros and the excellent inventory crate to reduce boilerplate and unlock new functionality for a job queue I built for this project.
The code is available here for the job queue and the supporting derive macros.
Disclaimer: This is an example of how I solved the problem. There's probably better ways to do this, but this worked fine for me within my constraints and I had fun writing it. Please don't use this code as is in production - I haven't gotten around to writing any unit tests or documentation yet
The problem
When building my side project, I needed a job queue. I didn't find one that quite met my needs at the time so, as any enterprising backend engineer is wont to do, I wrote my own. I'd been using a shitty, customized one for my own app, but grew frustrated at some of the limitations:
- For type safety, I had an enum to define all job types. But this was in the core
jobbycrate, so if I added a job type, I'd need to rebuild the world. I wanted to keep type safety, but have the enum somehow within each client crate.- This wasn't trivial, as I still had to ensure job IDs were unique (or we'd have painful conflicts)
- I wanted to build a UI on top to allow admin behavior, such as viewing all job statuses, restarting them, kicking off jobs, etc
- I didn't want to require a lot of boilerplate to register a job type and provide metadata
End user experience
For clarity, let's assume that we have one app with two distinct crates that need to run various jobs. Here's how this gets wired together, with one enum per client crate that needs to use jobby. In one of the crates (steam) I now define an enum like the below:
#[derive(Clone, Copy, Debug, jobby::JobType)]
#[repr(u8)]
#[job_type(3, "steam", JobbyModule)]
pub enum JobType {
FetchAppList = 0,
ProcessAppList = 1,
}
This references a JobbyModule in the same file which has code like the below
struct JobbyModule {
pool: ConnectionPool<Db>,
}
#[async_trait::async_trait]
impl jobby::Module for JobbyModule {
fn initialize(rocket: &Rocket<Build>) -> Result<Self, Error> {
Ok { pool: /* get from somewhere */ }
}
async fn workers(
&self,
registry: WorkerRegistry,
mode: WorkerCreationMode,
) -> Result<(), Error> {
// Register workers to process data for a given type. example:
registry.register(
Arc::new(ExecutorForURLFetchAndStoreJob(AppListFetcher {})),
"app_list_fetcher",
JobType::FetchAppList,
Duration::from_secs(5),
)?;
Ok(())
}
async fn jobs(&self, registry: JobRegistry, mode: JobCreationMode) -> Result<(), Error> {
// create jobs to run on startup
registry
.submit_job(JobType::FetchAppList, "sentinel")
.allowed_attempts(19)
.register(®istry);
registry
.submit_job(JobType::ProcessAppList, "sentinel")
.dependency(JobType::FetchAppList, "sentinel")
.allowed_attempts(7)
.register(®istry);
Ok(())
}
}
And that's it. As a user of jobby you don't need to do anything else, you can have type-safe job submissions, and the admin UI and everything else just works (tm). This user experience kept me happy.
So how does it work under the hood?
The solution
The solution involved a neat trick using the inventory crate to collect all the registered clients at startup, and a derive macro to abstract over some of the boilerplate code to provide metadata. I'll build this up from parts:
JobbyModule-- the interface clients must implementJobType-- the enum interface clients use to define their jobs- A
ClientModulethat abstracts over the two - Collecting all of those at runtime
- Deriving
JobTypeand setting upClientModule
JobbyModule
Each client crate is required to implement JobbyModule as shown above - this is a simple interface that provides some (created at runtime) workers and jobs:
#[async_trait::async_trait]
pub trait Module {
fn initialize(rocket: &Rocket<Build>) -> Result<Self, Error>
where
Self: Sized;
// Register workers for this module, when running in the given mode
async fn workers(
&self,
registry: WorkerRegistry,
mode: WorkerCreationMode,
) -> Result<(), Error>;
// Register jobs for this module, when running in the given mode
async fn jobs(&self, registry: JobRegistry, mode: JobCreationMode) -> Result<(), Error>;
}
JobType
Again, the user experience is demonstrated above. Under the hood, jobby expects the job type to actually be a trait as shown here - most notably it needs to describe each variant of the enum with additional metadata like its name, a unique ID, and so on. I didn't want to type this out, so we derive this later. The code is as follows
// A JobType suitable for declaring and using jobs.
// Do not implement this directly! Just declare a #[repr(u8)]
// enum, give values to all the discriminants, and use the derive macro
pub trait JobType: Into<u8> + Into<&'static str> {
// ID for this client. Must be globally unique
// Each client gets upto 256 job types
// We can eventually add more in the future, this is just easier
fn client_id() -> usize;
// List out the metadatas for each job type.
fn list_metadata() -> Vec<JobTypeMetadata>;
}
#[derive(Debug, Clone, Serialize)]
pub struct JobTypeMetadata {
pub unnamespaced_id: i64,
pub base_id: u8,
pub client_id: usize,
pub name: &'static str,
pub client_name: &'static str,
pub is_submittable: bool,
}
ClientModule
The ClientModule abstracts over both of these for the rest of the code in jobby. It looks like this:
type ModuleInitializer = fn(&Rocket<Build>) -> Result<Box<dyn Module + Send + Sync>, Error>;
type JobMetadataLister = fn() -> Vec<JobTypeMetadata>;
pub struct ClientModule {
pub(crate) id: usize,
pub(crate) name: &'static str,
pub(crate) module_initializer: ModuleInitializer,
pub(crate) job_metadata_lister: JobMetadataLister,
}
Collecting all the clients at runtime
You might have noticed the following line if you clicked through to the links:
inventory::collect!(ClientModule);This is super loadbearing. It tells the inventory to collect any instances of ClientModule that have been registered in the linked binary. We'll get to how those are done in the next section.
Assuming it magically works though, we just need to use inventory::iter and we're done. And that's what we do here
for client in inventory::iter::<ClientModule> {
if let Some(existing) = client_map.insert(client.id, client.name) {
return Err(Error::DuplicateClientId(client.id, existing, client.name));
}
if let Some(existing) = client_names.insert(client.name, client.id) {
return Err(Error::DuplicateClientName(client.name, client.id, existing));
}
metadata.register(client);
let module = (client.module_initializer)(rocket)?;
let registry = WorkerRegistry::new(client.name, Arc::clone(&workers));
module
.workers(registry, config.worker_creation_mode)
.await?;
let registry = JobRegistry::new(Arc::clone(&job_builders));
module.jobs(registry, config.job_creation_mode).await?;
}
TLDR:
- Ensure client name/ID is unique (or things horribly break)
- Update a metadata registry with the job names/IDs
- Call the user-defined initializer callbacks to initialize the module and then register any workers and jobs
Deriving JobType and setting up ClientModule
This is not a tutorial on how to write a derive macro, unfortunately. There's a lot of resources for that (and I suspect that AI might be able to do a decent job, though I did this a few years ago). The code is here. What's relevant for now is how the cargo-expand output looks like, which I've detailed below.
First we derive some From impls:
impl From<JobType> for u8 {
#[inline]
fn from(enum_value: JobType) -> Self {
enum_value as Self
}
}
impl From<JobType> for &'static str {
fn from(enum_value: JobType) -> Self {
match enum_value {
JobType::FetchAppList => "FetchAppList",
JobType::ProcessAppList => "ProcessAppList",
}
}
}
Then we implement JobType:
impl jobby::JobType for JobType {
#[inline]
fn client_id() -> usize {
3
}
fn list_metadata() -> Vec<jobby::JobTypeMetadata> {
<[_]>::into_vec(
#[rustc_box]
::alloc::boxed::Box::new([
jobby::JobTypeMetadata {
unnamespaced_id: jobby::UnnamespacedJobType::from(
Self::FetchAppList,
)
.id(),
base_id: 0,
client_id: 3,
name: "FetchAppList",
client_name: "steam",
is_submittable: false,
},
jobby::JobTypeMetadata {
unnamespaced_id: jobby::UnnamespacedJobType::from(
Self::ProcessAppList,
)
.id(),
base_id: 1,
client_id: 3,
name: "ProcessAppList",
client_name: "steam",
is_submittable: false,
},
]),
)
}
}
We wire up things properly by creating a static module that can be called from the relevant ClientModule:
mod jobby_init__JobType {
use jobby::JobType;
pub fn initialize(
rocket: &jobby::rocket::Rocket<jobby::rocket::Build>,
) -> Result<Box<dyn jobby::Module + Send + Sync>, jobby::Error> {
Ok(Box::new(<super::JobbyModule as jobby::Module>::initialize(rocket)?))
}
pub fn list_metadata() -> Vec<jobby::JobTypeMetadata> {
super::JobType::list_metadata()
}
}
Lastly, we do an inventory::submit! call which (relevant part cut out) does this important bit:
jobby::ClientModule::new(
3,
"steam",
jobby_init__JobType::initialize,
jobby_init__JobType::list_metadata,
)
Tooting my own horn: the admin UI
What's the point of doing all of that if just for some type safety? Is it really worth it?
Honestly I'd say no. But the fact is that with the derive macro in place I could add more metadata (e.g. job names, is_submittable, etc) which let me build some useful helpers to build an admin UI on top. While the UI isn't open sourced yet, you can see the helpers here.
This lets me build a fun admin UI that can do the following:
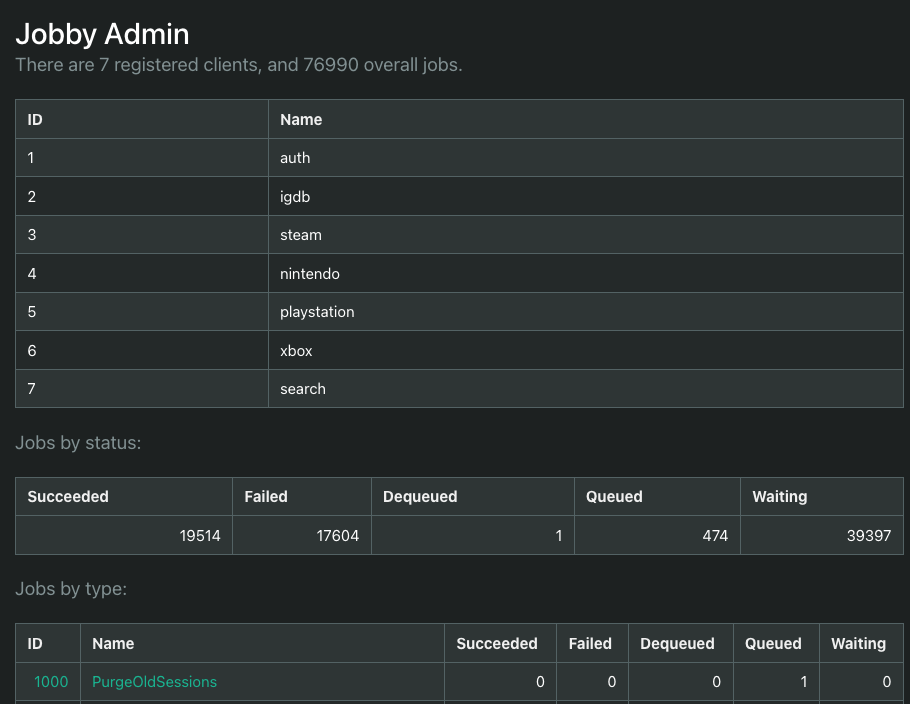
Overview of all jobs and registered modules
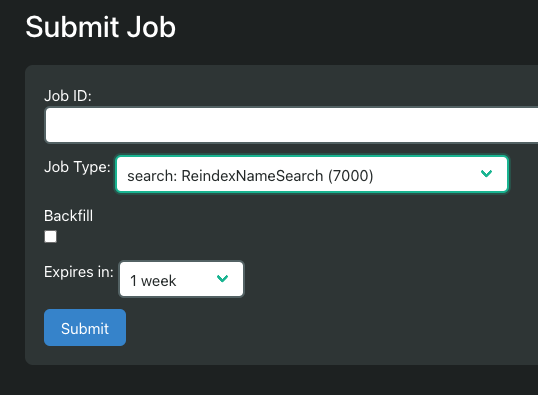
UI to submit job
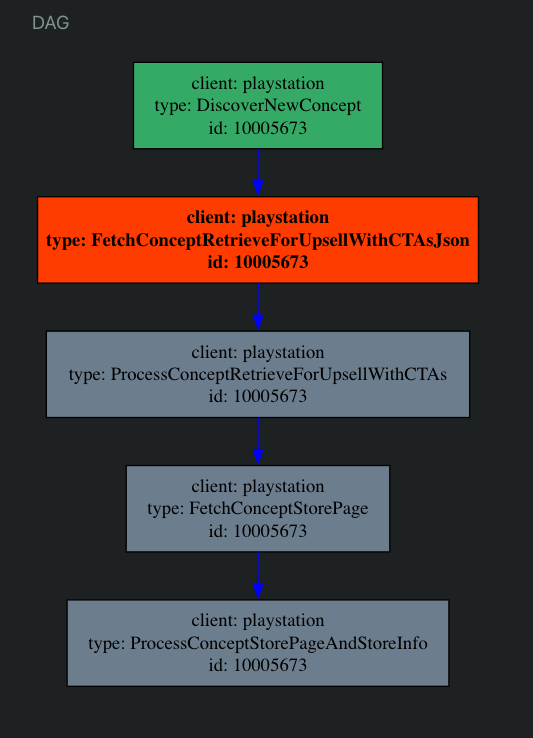
DAG for a real workflow
I used this a lot to debug failed jobs, measure timings for how long things ran, see input/output sizes, etc (not all of those things are pictured due to brevity). and that wouldn't have happened were it not for this.
TLDR
Thanks for reading this far. To recap, the main point of this post is that derive macros can be your friend if used judiciously, and the inventory crate unlocks additional usecases if you want to work on a larger decentralized codebase. Type-safe solutions are fun and can enable efficient solutions to problems that wouldn't work well otherwise.
Oh and please don't use my code here, it sucks.